
KUDO, Inc.
Visual Cues as Comprehension Aids: The Missing Link in Machine Interpreting

Most of the time, live communication takes place using both verbal and non-verbal means, adapted to the situational needs and communicative goals of the interlocutors. Of course, this also plays a crucial role in multilingual communication and machine interpretation.
A typical verbal means is topicalization, i.e. placing the most salient part of the information at the beginning of a sentence in order to convey a specific meaning.
For example: A sentence like "I won't eat that pizza" can be transformed into "That pizza I won't eat" to emphasize that you won't eat that particular pizza, but you will eat the one next to it, possibly expressing a certain level of disgust with the first one (it might have pineapple!).
As for non-verbal means, speakers can look at what they are referring to in order to improve the listener's understanding.
For example: If someone says, "That's really big," while looking at a particular object, the listener will immediately know what "that" is, perhaps a piece of cake. In the absence of a visual context, one might wonder about the reference. What is meant by "that"? In the context of multilingual communication, a literal translation may suffice, or it may miss the mark. With widened eyes and raised eyebrows suggesting astonishment, it becomes clear that the individual is conveying shock or amazement rather than asking for an explanation of what a particular object is.
I’ve previously explored sentiment analysis from video, highlighting the potential for such visual cues, such as facial expressions or body language, to inform more nuanced translations. Similarly, knowing the objects in a room, how people are dressed, down to the color of their clothes, whether or not they wear glasses, and so on, could become important information to better understand the meaning of what people are saying. In other words, vision plays an important role in live translation. And while it is certainly possible to communicate without visual cues, it is clear that some aspects of communication will be compromised.
One of the greatest challenges of machine interpretation is precisely this: its inability to perceive visual cues. Machine interpretation is unimodal. To make sense of the situation, translation decisions are based solely on linguistic cues, overlooking other important levels of communication, such as visual stimuli. Neural Machine Translation (NMT), for example, is unimodal. Larger language models, an important evolution in machine translation, are also unimodal. While they introduce some level of contextual reasoning, as I discussed in my post on Situational Awareness in Machine Interpreting, potentially improving translation quality over NMT through contextualization, they remain inherently dependent only on the language input.
What if we could now add visual information to the translation process?
The leap towards vision-enhanced machine interpreting may be just around the corner (i.e., a few years from now). Newly released vision systems combined with large language models have an impressive ability to dissect images, with live video analysis just a step away, and are now able to transform visual data into what I call, for lack of a better term, situational meta-information (i.e., what we see). This can be used to enrich the translation process and achieve higher levels of quality and accuracy.

Let's examine what we can learn today from this image (Figure 1), which can be captured from a real-time video feed. The scene is a typical stage setting. For example, we'd like to generate situational meta-information about the three speakers, their clothing, and other relevant details to aid in the translation process. With appropriate prompting, a large language model such as GPT-4 combined with a vision system can provide the descriptions shown in Figure 2.

The depth and granularity of the description is striking. The type of information that can be retrieved and the level of detail can be tailored to specific needs. There's a wealth of information that can be extracted. Not only information about the people as in the example, but also details about the setting, information about the posters in the background, etc. What for? For example, consider the level of formality that the venue might dictate. If we know this information, we can adjust the formality of the translation accordingly.
To make this information computer-friendly, especially for a large language model tasked with translation, we need to structure this data systematically. Well-structured meta-information about the situation can then be used in the translation process by means of frame and scene prompting. Fortunately, structuring data in a computer-friendly way is straightforward. With a few iterations of prompting, we can derive a nice structure of the extracted metadata, as shown in Figure 3.
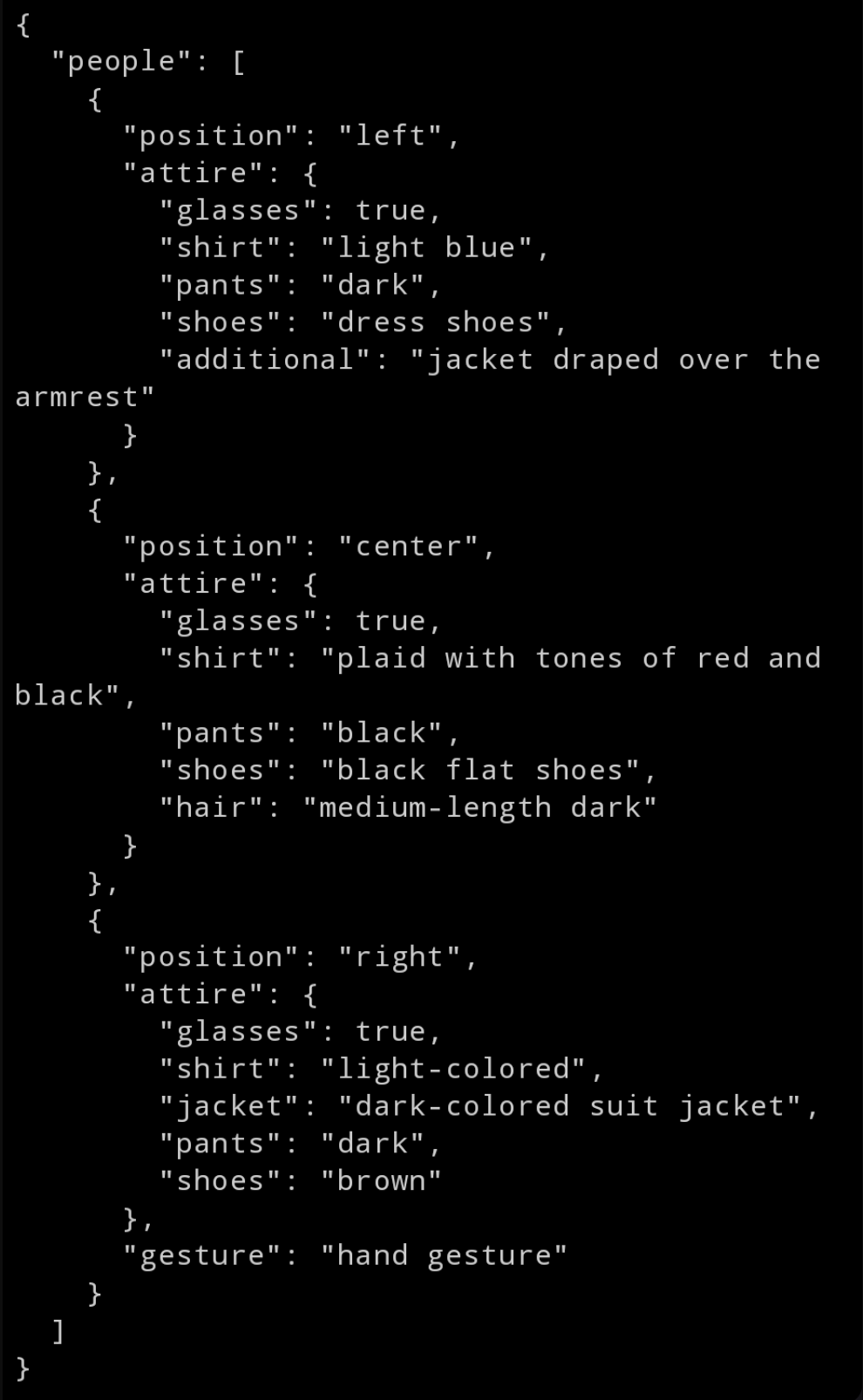
The key to this approach is that we've achieved - fully automatically - a detailed understanding of the scene, in this case the speakers' clothing. In speech translation, this data can be used to refine translation decisions.
Such an improvement in speech translation is powerful. This is primarily because it mimics the innate process that humans engage in every day, consciously or unconsciously, during interpersonal communication: triangulating multiple sources of information to understand the meaning of what people are saying. In other words, it helps ground the translation process in the reality of the communicative setting.
The road ahead is long and there are many unknowns, but once again, the trajectory seems clear. Speech translation systems may grow exponentially in complexity. But multilingual communication is indeed complex. If you want to achieve high quality translation, we will have to go down this path of complexity (at least until scaling or new approaches - maybe - solve translation quality problems themselves).
Tip
You can try Lava, an open-sourced version of a multimodal model.
Do you want to contribute with an article, a blog post or a webinar?
We’re always on the lookout for informative, useful and well-researched content relative to our industry.

Claudio Fantinuoli
Claudio is Chief Technology Officer at KUDO Inc., a company specialized in delivering human and AI live interpretation. The latest product is the KUDO AI Translator, a real-time, continuous speech-to-speech translation system. Claudio is also Lecturer and Researcher at the University of Mainz and Founder of InterpretBank, an AI-tool for professional interpreters.